Abstract: In this work, we propose a novel robot learning framework called Neural Task Programming (NTP), which bridges the idea of few-shot learning from demonstration and neural program induction. NTP takes as input a task specification (e.g., video demonstration of a task) and recursively decomposes it into finer sub-task specifications. These specifications are fed to a hierarchical neural program, where bottom-level programs are callable subroutines that interact with the environment. We validate our method in three robot manipulation tasks. NTP achieves strong generalization across sequential tasks that exhibit hierarchal and compositional structures. The experimental results show that NTP learns to generalize well towards unseen tasks with increasing lengths, variable topologies, and changing objectives.
Giffen goods are highly elusive things. Named after Sir Robert Giffen, who first proposed their existence, Giffen goods are unique in that as their prices rise, people respond by demanding more of the good in question.
By contrast, given the way the forces of supply and demand usually work, when the price of a good rises, people respond by demanding lower quantities of the good.
To understand why Giffen goods are different, let's take a closer look at the conditions that makes a Giffen unique (excerpting Wikipedia) in leading their quantity demanded to rise in response to an increase in their price:
There are three necessary preconditions for this situation to arise:
the good must constitute a substantial percentage of the buyer's income, but not such a substantial percentage of the buyer's income that none of the associated normal goods are consumed.
If precondition #1 is changed to "The good in question must be so inferior that the income effect is greater than the substitution effect" then this list defines necessary and sufficient conditions. As the last condition is a condition on the buyer rather than the good itself, the phenomenon can also be labeled as "Giffen behavior".
Unfortunately, Giffen goods are rarely found in the real world. Wikipedia explains why:
Giffen goods are difficult to find because a number of conditions must be satisfied for the associated behavior to be observed. One reason for the difficulty in finding Giffen goods is Giffen originally envisioned a specific situation faced by individuals in a state of poverty. Modern consumer behaviour research methods often deal in aggregates that average out income levels and are too blunt an instrument to capture these specific situations. Furthermore, complicating the matter are the requirements for limited availability of substitutes, as well as that the consumers are not so poor that they can only afford the inferior good. It is for this reason that many text books use the term Giffen paradox rather than Giffen good.
It occurs to us that, under certain circumstances, debt might be considered to be a Giffen good. Let's go through each of the three conditions necessary for a Giffen good to exist to see how debt stacks up.
Debt as an Inferior Good
To qualify as an inferior good, an individual's demand for the good must decrease as their income rises. Keeping that basic definition in mind, we turned to the Federal Reserve's Changes in U.S. Family Finances from 2004 to 2007: Evidence from the Survey of Consumer Finances. The chart to the right presents the leverage ratio for U.S. families according to their income percentile for the years 1998, 2001, 2004 and 2007, which we extracted from Table 12 of the Fed's study.
What we find is that as income rises from the lowest income percentiles, the leverage ratio of U.S. households first increases, then somewhere between the 60th and 80th percentiles (between an annual family income of $59,600 and $98,200 in 2007), the leverage ratio for U.S. households falls.
What this relationship suggests is that debt does indeed qualify as being an inferior good.
A Lack of Substitutes for Debt
Having established that debt qualifies as being an inferior good, we'll next consider what substitutes might exist for it. We'll do that by returning to debt's characteristics as an inferior good, and consider the answers to two pretty simple questions:
Could higher income households sustain a higher leverage ratio?
Do they?
The answer to the first question is "Yes." The answer to the second question is "No." That latter question is important because by considering why the answer to it is "no", we can identify the substitutes that exist for debt.
We observe in our chart of leverage ratios with respect to household income, that as households see their incomes rise or as they accumulate assets, they don't take on higher levels of debt. This makes sense since these households might either opt to pay cash for things out of their flow of income, or they might sell assets they already own to cover part or all of the cost of the things they might wish to acquire. In both cases, they have the ability to take on more debt, but choose not to do so, because they prefer these other options to it.
However, households at lower income levels would appear to lack these alternative means of acquiring goods, or at least have much less alternative options to work with compared to households with greater levels of income and assets, which confirms their lack of close substitutes to debt for the lower income households.
Debt Consumes A Significant Portion of Income, But Not Too Much
This third and final condition is almost redundant at this point, but we can firm that debt consumes a significant portion of income, but not too much, by returning to the Fed's study of consumer finances and looking at the median ratio of debt payments to family income percentile, which we've presented in the chart to the right.
The chart confirms that for lower income families, the median ratio of debt payments to their household income ranges between 16 and 22% up into the range of the 60th and 80th percentiles for household income. Above this level, we see the ratio of debt payments to family income fall, but we confirm that debt does indeed consume a significant portion of income, but not too much.
Empirical Evidence
Having established that debt qualifies as being a candidate for being a Giffen good, let's consider the evidence that consumers respond to an increase in the cost of debt by demanding greater quantities of it. Here, we identify a unique circumstance that does indeed transform debt from simply being an inferior good into a Giffen good: when after a period of falling interest rates, interest rates (or rather, the price of debt) begin to rise!
The following news articles from recent years reveal the increase in debt demanded as the cost of debt increases during these times:
In each of these cases, the borrowers were seeking to acquire debt as they anticipated having to pay a higher cost for the debt later (in the form of higher interest rates) if they delayed. As a result, the increases in the price of debt drove an increase in the quantity of debt demanded.
Admittedly, the situation we describe is of only limited duration, however it cannot be denied that it does occur and does result in debt becoming a Giffen good. And if so, the most common.
Abstract
We report a method to convert discrete representations of molecules to and from
a multidimensional continuous representation. This model allows us to generate new
molecules for efficient exploration and optimization through open-ended spaces of
chemical compounds.
1
arXiv:1610.02415v3 [cs.LG] 5 Dec 2017
A deep neural network was trained on hundreds of thousands of existing chemical
structures to construct three coupled functions: an encoder, a decoder and a predictor.
The encoder converts the discrete representation of a molecule into a real-valued
continuous vector, and the decoder converts these continuous vectors back to discrete
molecular representations.
The predictor estimates chemical properties from the latent
continuous vector representation of the molecule.
Continuous representations allow us to automatically generate novel chemical structures
by performing simple operations in the latent space, such as decoding random
vectors, perturbing known chemical structures, or interpolating between molecules.
Continuous representations also allow the use of powerful gradient-based optimization
to efficiently guide the search for optimized functional compounds. We demonstrate
our method in the domain of drug-like molecules and also in the set of molecules with
fewer that nine heavy atoms.
Link: https://arxiv.org/pdf/1610.02415.pdf
Methods
Autoencoder architecture Strings of characters can be encoded into vectors using recurrent
neural networks (RNNs). An encoder RNN can be paired with a decoder RNN to
perform sequence-to-sequence learning. 45 We also experimented with convolutional networks
for string encoding 46 and observed improved performance. This is explained by the presence
of repetitive, translationally-invariant substrings that correspond to chemical substructures,
e.g., cycles and functional groups.
Our SMILES-based text encoding used a subset of 35 different characters for ZINC and 22
different characters for QM9. For ease of computation, we encoded strings up to a maximum
length of 120 characters for ZINC and 34 characters for QM9, although in principle there is
no hard limit to string length. Shorter strings were padded with spaces to this same length.
We used only canonicalized SMILES for training to avoid dealing with equivalent SMILES
representations. The structure of the VAE deep network was as follows: For the autoencoder
used for the ZINC dataset, the encoder used three 1D convolutional layers of filter sizes 9,
9, 10 and 9, 9, 11 convolution kernels, respectively, followed by one fully-connected layer of
width 196. The decoder fed into three layers of gated recurrent unit (GRU) networks 47 with
hidden dimension of 488. For the model used for the QM9 dataset, the encoder used three
13
1D convolutional layers of filter sizes 2, 2, 1 and 5, 5, 4 convolution kernels, respectively,
followed by one fully-connected layer of width 156.
The three recurrent neural network layers
each had a hidden dimension of 500 neurons.
The last layer of the RNN decoder defines a probability distribution over all possible
characters at each position in the SMILES string. This means that the writeout operation is
stochastic, and the same point in latent space may decode into to different SMILES strings,
depending on the random seed used to sample characters. The output GRU layer had one
additional input, corresponding to the character sampled from the softmax output of the
previous time step and was trained using teacher forcing. 48 This increased the accuracy
of generated SMILES strings, which resulted in higher fractions of valid SMILES strings
for latent points outside the training data, but also made training more difficult, since the
decoder showed a tendency to ignore the (variational) encoding and rely solely on the input
sequence. The variational loss was annealed according to sigmoid schedule after 29 epochs,
running for a total 120 epochs.
For property prediction, two fully connected layers of 1000 neurons were used to predict
properties from the latent representation, with a dropout rate of 0.2. For the algorithm
trained on the ZINC dataset, the objective properties include logP, QED, SAS. For the
algorithm trained on the QM9 dataset, the objective properties include HOMO energies,
LUMO energies, and the electronic spatial extent (R2
). The property prediction loss was
annealed in at the same time as the variational loss. We used the Keras 49 and TensorFlow50
packages to build and train this model and the rdkit package for cheminformatics. 28
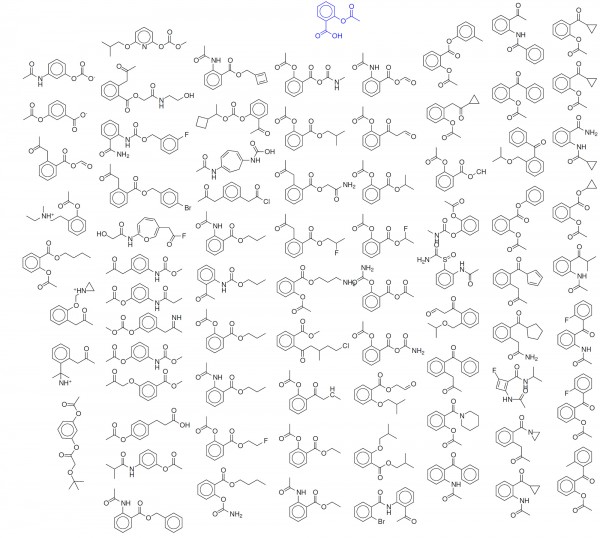
What do you get if you cross aspirin with ibuprofen? Harvard chemistry professor Alán Aspuru-Guzik isn’t sure, but he’s trained software that could give him an answer by suggesting a molecular structure that combines properties of both drugs.
The AI program could help the search for new drug compounds. Pharmaceutical research tends to rely on software that exhaustively crawls through giant pools of candidate molecules using rules written by chemists, and simulations that try to identify or predict useful structures. The former relies on humans thinking of everything, while the latter is limited by the accuracy of simulations and the computing power required.
Aspuru-Guzik’s system can dream up structures more independently of humans and without lengthy simulations. It leverages its own experience, built up by training machine-learning algorithms with data on hundreds of thousands of drug-like molecules.
"It explores more intuitively, using chemical knowledge it learned, like a chemist would," says Aspuru-Guzik. "Humans could be better chemists with this kind of software as their assistant." Aspuru-Guzik was named to MIT Technology Review’s list of young innovators in 2010.
The new system was built using a machine-learning technique called deep learning, which has become pervasive in computing companies but is less established in the natural sciences. It uses a design known as a generative model, which takes in a trove of data and uses what it learned to generate plausible new data of its own.
Generative models are more typically used to create images, speech, or text, for example in the case of Google’s Smart Reply feature that suggests responses to e-mails. But last month Aspuru-Guzik and colleagues at Harvard, the University of Toronto, and the University of Cambridge published results from creating a generative model trained on 250,000 drug-like molecules.
The system could generate plausible new structures by combining properties of existing drug compounds, and be asked to suggest molecules that strongly displayed certain properties such as solubility, and being easy to synthesize.
Vijay Pande, a professor of chemistry at Stanford and partner with venture capital firm Andreessen Horowitz, says the project adds to the growing evidence that new ideas in machine learning will transform scientific research (see “Stopping Breast Cancer with Help from AI”).
It suggests that deep-learning software can internalize a kind of chemical knowledge, and use it to help scientists, he says. “I think this could be very broadly applicable,” says Pande. “It could play a role in finding or optimizing lead drug candidates, or other areas like solar cells or catalysts.”
The researchers have already experimented with training their system on a database of organic LED molecules, which are important for displays. But making the technique into a practical tool will require improving its chemistry skills, because the structures it suggests are sometimes nonsensical.
Pande says one challenge for asking software to learn chemistry may be that researchers have not yet identified the best data format to use to feed chemical structures into deep-learning software. Images, speech, and text have proven to be a good fit—as evidenced by software that rivals humans at image and speech recognition and translation—but existing ways of encoding chemical structures may not be quite right.
Aspuru-Guzik and his colleagues are thinking about that, along with adding new features to his system to reduce its chemical blooper rate.
He also hopes that giving his system more data, to broaden its chemistry knowledge, will improve its power, in the same way that databases of millions of photos have helped image recognition become useful. The American Chemical Society’s database records around 100 million published chemical structures. Before long, Aspuru-Guzik hopes to feed all of them to a version of his AI program.
Hear more about AI from the experts at the EmTech Digital Conference, March 26-27, 2018 in San Francisco.

 To qualify as an inferior good, an individual's demand for the good must decrease as their income rises. Keeping that basic definition in mind, we turned to the Federal Reserve's Changes in U.S. Family Finances from 2004 to 2007: Evidence from the Survey of Consumer Finances. The chart to the right presents the leverage ratio for U.S. families according to their income percentile for the years 1998, 2001, 2004 and 2007, which we extracted from Table 12 of the Fed's study.
To qualify as an inferior good, an individual's demand for the good must decrease as their income rises. Keeping that basic definition in mind, we turned to the Federal Reserve's Changes in U.S. Family Finances from 2004 to 2007: Evidence from the Survey of Consumer Finances. The chart to the right presents the leverage ratio for U.S. families according to their income percentile for the years 1998, 2001, 2004 and 2007, which we extracted from Table 12 of the Fed's study. This third and final condition is almost redundant at this point, but we can firm that debt consumes a significant portion of income, but not too much, by returning to the Fed's study of consumer finances and looking at the median ratio of debt payments to family income percentile, which we've presented in the chart to the right.
This third and final condition is almost redundant at this point, but we can firm that debt consumes a significant portion of income, but not too much, by returning to the Fed's study of consumer finances and looking at the median ratio of debt payments to family income percentile, which we've presented in the chart to the right.